


Big Data
- 14 de ago. de 2024
- 3 min de leitura
Atualizado: 16 de ago. de 2024

Big Data é um termo que descreve volumes massivos de dados que não podem ser facilmente geridos, processados ou analisados utilizando métodos tradicionais.
Esses dados podem vir de diversas fontes, como sensores, dispositivos conectados, redes sociais, transações financeiras, registros médicos, entre outros.
APLICAÇÃO
ANÁLISE DE NEGÓCIOS Big Data é amplamente utilizado para melhorar a eficiência operacional, identificar oportunidades de mercado e aumentar a satisfação do cliente.

SAÚDE Big Data está revolucionando o setor de saúde ao permitir uma análise mais eficiente e precisa dos dados médicos.

INTERNET DAS COISAS (IOT) Big Data é essencial para analisar e extrair valor dos dados gerados por dispositivos conectados.

F. CIÊNCIA E PESQUISA Big Data desempenha um papel crucial na aceleração da pesquisa científica e na descoberta de novos conhecimentos.
OS TRÊS "V"s DA BIG DATA
1. VOLUME
Refere-se à grande quantidade de dados gerados e armazenados. O volume de dados gerado globalmente cresce exponencialmente e pode incluir petabytes ou exabytes de dados.
2. VELOCIDADE
Refere-se à velocidade com que os dados são gerados, processados e analisados. A capacidade de lidar com dados em tempo real é crucial para muitas aplicações de Big Data.
3. VARIEDADE
Refere-se à diversidade de tipos e fontes de dados. Big Data inclui dados estruturados, semiestruturados e não estruturados provenientes de diferentes fontes.
ETAPAS
Uma arquitetura de Big Data bem projetada deve ser escalável, flexível, resiliente e capaz de lidar com dados de diversas fontes e formatos.
1. FONTE DE DADOS
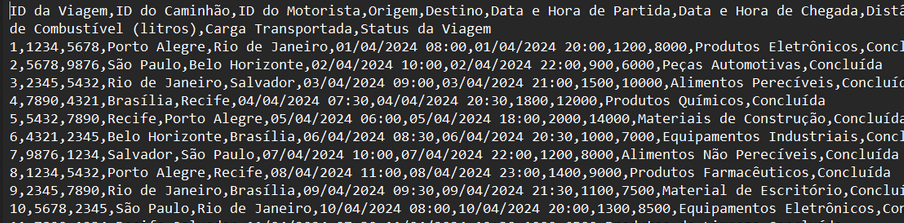
Dados Estruturados: Bancos de dados relacionais, arquivos CSV.
Dados Semiestruturados: JSON, XML.
Dados Não Estruturados: Texto, imagens, vídeos, logs.
Dados de Streaming:
2. INGESTÃO DE DADOS

Ferramentas para coleta e transporte de dados
3. ARMAZENAMENTO DE DADOS

Data Lakes
Data Warehouses
Sistemas de Arquivos Distribuídos: HDFS, Amazon S3.
4. PROCESSAMENTO DE DADOS

Batch Processing: Processamento de grandes volumes de dados em lotes.
Stream Processing: Processamento de dados em tempo real.
5. ANÁLISE DE DADOS
Data Mining
Machine Learning
Consultas e Análises Ad Hoc: SQL-on-Hadoop.
6. VISUALIZAÇÃO DE DADOS:
Ferramentas para criação de gráficos e dashboards interativos.
TECNOLOGIAS
HADOOP
Um framework open-source para armazenamento distribuído e processamento paralelo de grandes volumes de dados.

Hadoop é uma plataforma que permite o armazenamento distribuído e o processamento paralelo de grandes conjuntos de dados em clusters de computadores usando um modelo de programação simples.
COMPONENTES PRINCIPAIS:
HDFS
Sistema de arquivos distribuído que armazena dados em vários nós.

MAPREDUCE
Modelo de programação para processamento paralelo de grandes volumes

YARN
É constituído por uma estrutura de agendamento de tarefas e gestão de recursos de cluster; sistema de arquivos distribuídos ─ é responsável por fornecer acesso rápido aos dados da aplicação Hadoop.
APACHE SPARK
Apache Spark é um motor de processamento de dados em tempo real que suporta processamento em batch, processamento em tempo real (streaming), aprendizado de máquina e análise de gráficos.

Processamento em tempo real, alta velocidade, facilidade de uso, integração com outras ferramentas de Big Data.
COMPONENTES PRINCIPAIS:
SPARK CORE: Núcleo do Spark que gerencia tarefas de processamento.
SPARK SQL: Módulo para trabalhar com dados estruturados usando SQL.
SPARK STREAMING: Processamento de dados em tempo real.
MLLIB: Biblioteca de aprendizado de máquina.
GRAPHX: Biblioteca para processamento de gráficos.
NOSQL

Bancos de dados projetados para armazenamento e consulta de dados não estruturados ou semi-estruturados.
MONGODB

Banco de dados orientado a documentos que armazena dados em formato BSON (Binary JSON).
Flexibilidade no armazenamento de dados, escalabilidade horizontal, consultas poderosas.
CASSANDRA

Banco de dados distribuído e descentralizado projetado para lidar com grandes volumes de dados distribuídos em vários servidores.
Alta disponibilidade, escalabilidade linear, tolerância a falhas.
ELASTICSEARCH

Motor de busca e análise distribuído baseado em Apache Lucene.
Benefícios: Capacidade de pesquisa full-text, escalabilidade, integração com o stack ELK (Elasticsearch, Logstash, Kibana).
HBASE

Banco de dados NoSQL distribuído, projetado para fornecer acesso aleatório e em tempo real a grandes quantidades de dados estruturados.
FERRAMENTAS DE VISUALIZAÇÃO DE DADOS
TABLEAU
Ferramenta de visualização de dados que permite criar gráficos, dashboards e relatórios interativos.

Benefícios: Interface intuitiva, integração com várias fontes de dados, capacidade de criar visualizações complexas sem programação.
POWER BI
Ferramenta de análise de negócios da Microsoft que permite a criação de dashboards interativos e relatórios.
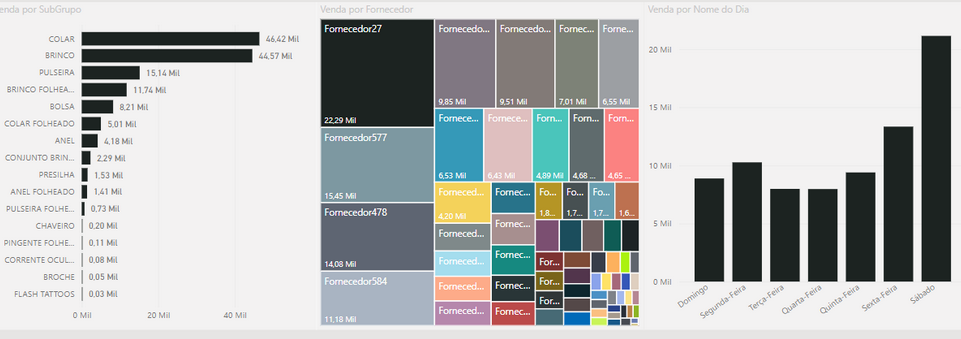
Benefícios: Integração com produtos Microsoft, facilidade de uso, recursos avançados de análise e visualização.
D3.JS

Biblioteca JavaScript para produzir visualizações de dados dinâmicas e interativas no navegador web.
Benefícios: Flexibilidade, personalização, capacidade de criar visualizações sofisticadas e interativas.
DATA CENTERS
DATA LAKES

Data Lakes são repositórios centralizados que permitem armazenar dados estruturados, semiestruturados e não estruturados em sua forma bruta.
DATA WAREHOUSES

Data Warehouses são repositórios centralizados para armazenar dados estruturados e processados, otimizados para consultas e análises.
DATA LAKEHOUSE

É uma arquitetura que combina elementos de data warehouses e data lakes para oferecer o melhor dos dois mundos.
___________________________________



Comentários